
Leveraging Vision-Language Models to Select Trustworthy Super-Resolution Samples Generated by Diffusion Models
Authors: Cansu Korkmaz, A. Murat Tekalp, Zafer Dogan
Venue: IEEE Transactions on Circuits and Systems for Video Technology - Special Issue on Large Language Models for Video Understanding, 2025
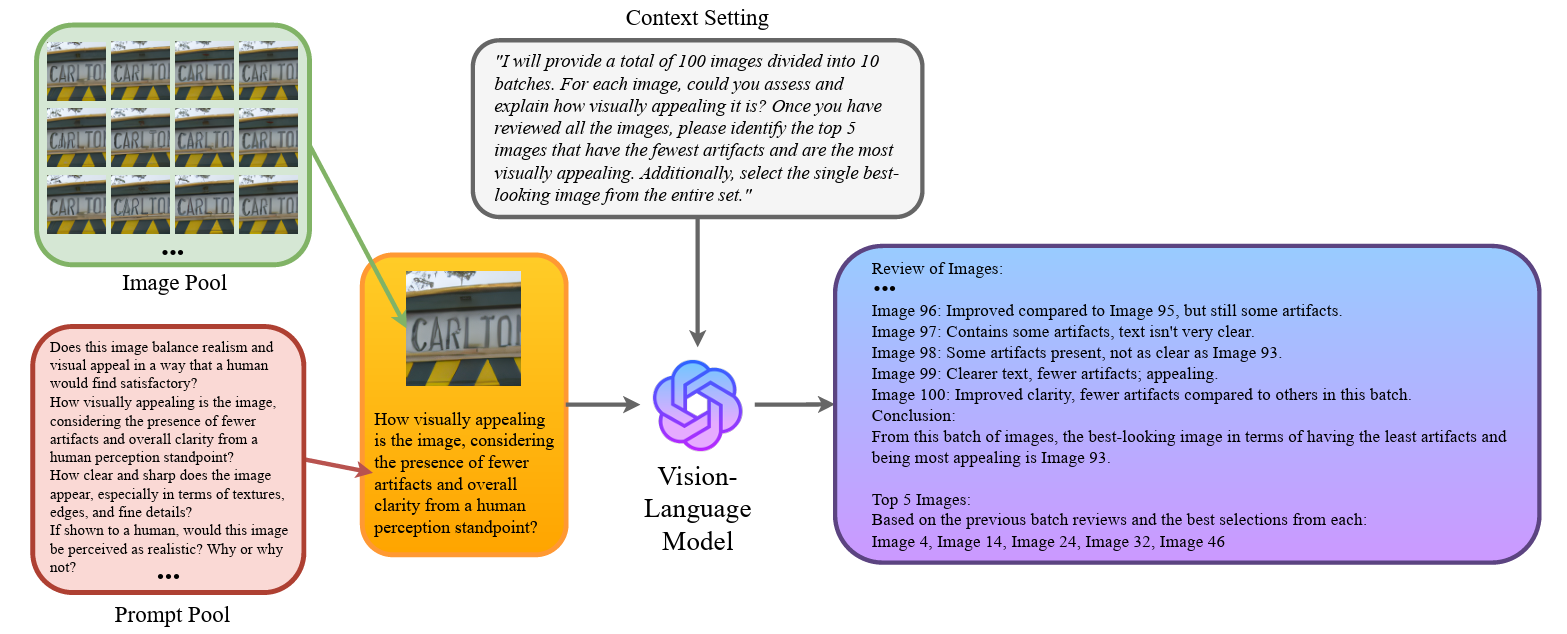
Overview
This paper addresses trustworthy super-resolution through intelligent sample selection in the latent space of diffusion models. By carefully selecting samples from the space spanned by latent diffusion models, the method ensures reliable and high-quality super-resolution results while maintaining trustworthiness and avoiding hallucination artifacts.
Key Contributions
- Sample selection strategy in latent diffusion space
- Trustworthy super-resolution framework
- Reduced hallucination and improved reliability