
Training Transformer Models by Wavelet Losses Improves Quantitative and Visual Performance in Single Image Super-Resolution
Authors: Cansu Korkmaz, A. Murat Tekalp, Zafer Dogan
Venue: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024
Overview
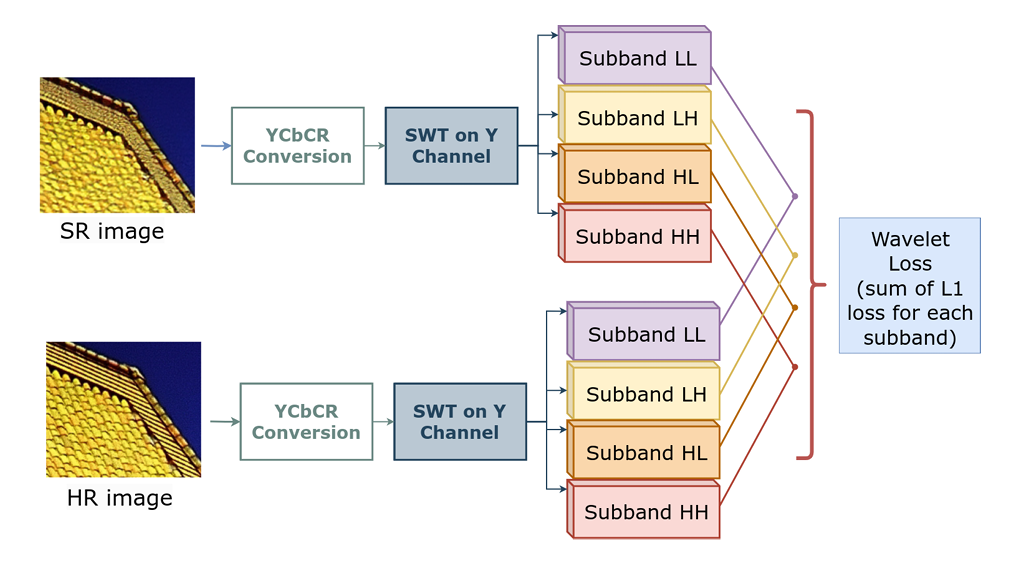
This work demonstrates that training transformer models with wavelet-domain losses significantly improves both quantitative metrics and visual quality in single image super-resolution tasks. By leveraging the multi-scale and frequency-localized properties of wavelets, the method achieves better artifact control and perceptual quality compared to standard pixel-domain losses.
Key Contributions
- Wavelet-domain loss functions for transformer training
- Improved quantitative and visual performance
- Better artifact control in super-resolution